Formal Dreams, Stochastic Streams
Sep 25, 2023
In the near past, I have written about the tension between logic and probability. To put it briefly, I have written how modern deep learning models are so good at statistical estimates of successive time steps, that regardless of the general criticism of ‘It doesn’t know what it’s talking about’, there may come a time when its generations are virtually indistinguishable from what one may consider a ‘reasonable logical sequence’. In fact, most middle school essays written by software running on GPT-4 should have no issues passing the eye test.
How, then, does one go about thinking about this issue?
By logic, we mean classical logic systems, not necessarily constrained to the Boolean mindset. In an Aristotelian sense, one could think about the simple premise-conclusion framework.
If A then B.
Premise A: Every human being is an animal
Premise B: Every animal needs food to survive
Conclusion: Every human being needs food to survive
Such syllogisms, or deductive reasoning, have been around since at least the Greeks. The notion of using statements such as “If this is true” to evaluate other statements such as “If the previous was true, this implies the following to also be true”, and so on and so forth, and virtually all of the propositional logic (A and B, A or B, A and (A or B), and chains of such) encompasses the formal framework.
Logic is important because it gives us a sense of precision. It gives us a structure of how concepts interact with each other in thought, and approximatively in language (more on language, later).
All the elementary algebraic operations we first encountered in grade school, such as the associative and distributive properties, emanate from propositional logic. In fact, the whole 2000 years of modern Western thought is more about formal logic than anything else. The notion of uncertainty and estimates gathered steam early in the 20th century, with the revolutions in quantum physics.
But this is not about choosing one system of thought over another. It is about recognizing what system of thought one idea belongs to, and how the other system could be incorporated into it.
As I have written before, the history of AI is replete with more examples of formal (symbolic) logic than statistics, while modern AI (the last decade) has shown unfathomable progress with uncertainty. However the shortcomings of uncertainty (and the possible exhaustion of model performance) have come to light, and the need arises for incorporating the old investigations anew.
How, then, do we think about formal logic and deep learning?
The answer lies with Stephen Wolfram.
If you have had any encounters with science/mathematics in your life, you have already heard of him. For everyone else, a short introduction of Stephen Wolfram is as follows: He is a bonafide legend.
In 1986, Stephen Wolfram left UIUC and founded the company Mathematica - a software to, well, do mathematics - Solve equations, plot functions, run simulations, etc. Next, he founded Wolfram Alpha, a system for doing similar things, but this time, based on natural language prompts.
Did you see a familiar term there - Prompts?
The potential of using natural language to accomplish tasks is as fundamental to the history of deep learning as it is to the history of computation.
Over the decades, Mathematica and Wolfram Alpha have become the de-facto software in every physics, chemistry, mathematics, astronomy (basically anything that you relate with the word “Science”), department in the world. Ask around, and you’ll know just how embedded this system is in training (and assisting) our technical researchers.
In fact, all noob data scientists that begin their training by running code cells on Jupyter are implicitly writing an ode to Wolfram, who created executable code kernels almost five decades ago.
What’s the difference between Wolfram Alpha and chatGPT? Well, what’s the difference between formal logic and stochastic streams of data?
Wolfram Alpha runs on Wolfram Language, a symbolic language designed specifically to turn natural language prompts into a codex that the Wolfram computing engine understands. Here’s an example:
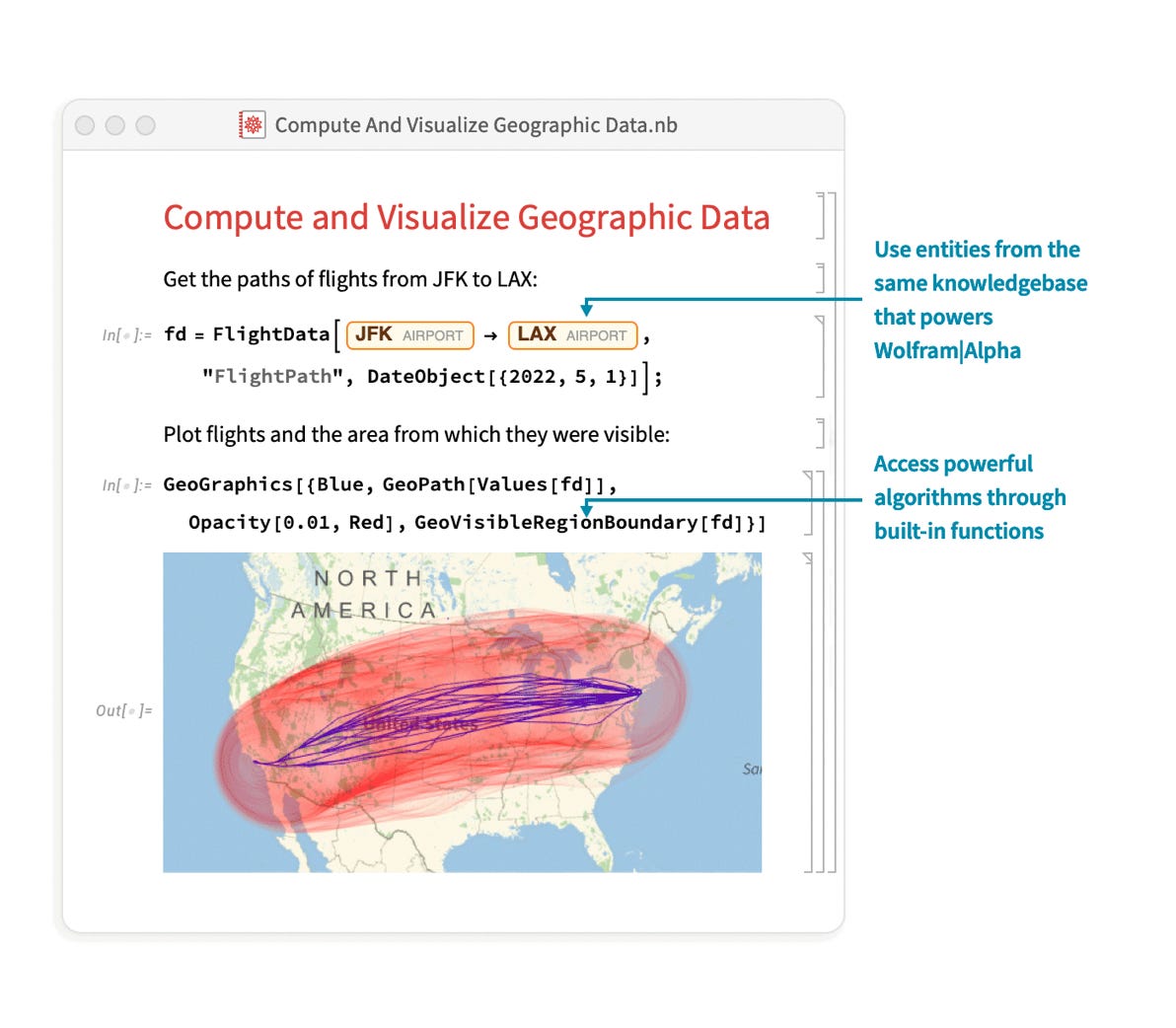
https://www.wolfram.com/language/
Let’s say you want to know the distance between Los Angeles and New York. You could ask chatGPT this, go on, try it out.
In all likelihood, the answer will be plain wrong.
Why? Because a notion of distance employs no notion of uncertainty. Given two geo-coordinates, one can compute the geodesic (fancy way of saying the distance on spherical objects) distance between the two points. One doesn’t need to infer the distance based on what data it has been trained on. This is a formal specification, not a statistical one.
In fact, Wolfram tries out many such examples on his blog (highly readable and a dense motherlode of interesting ideas). Here’s one of my favorites
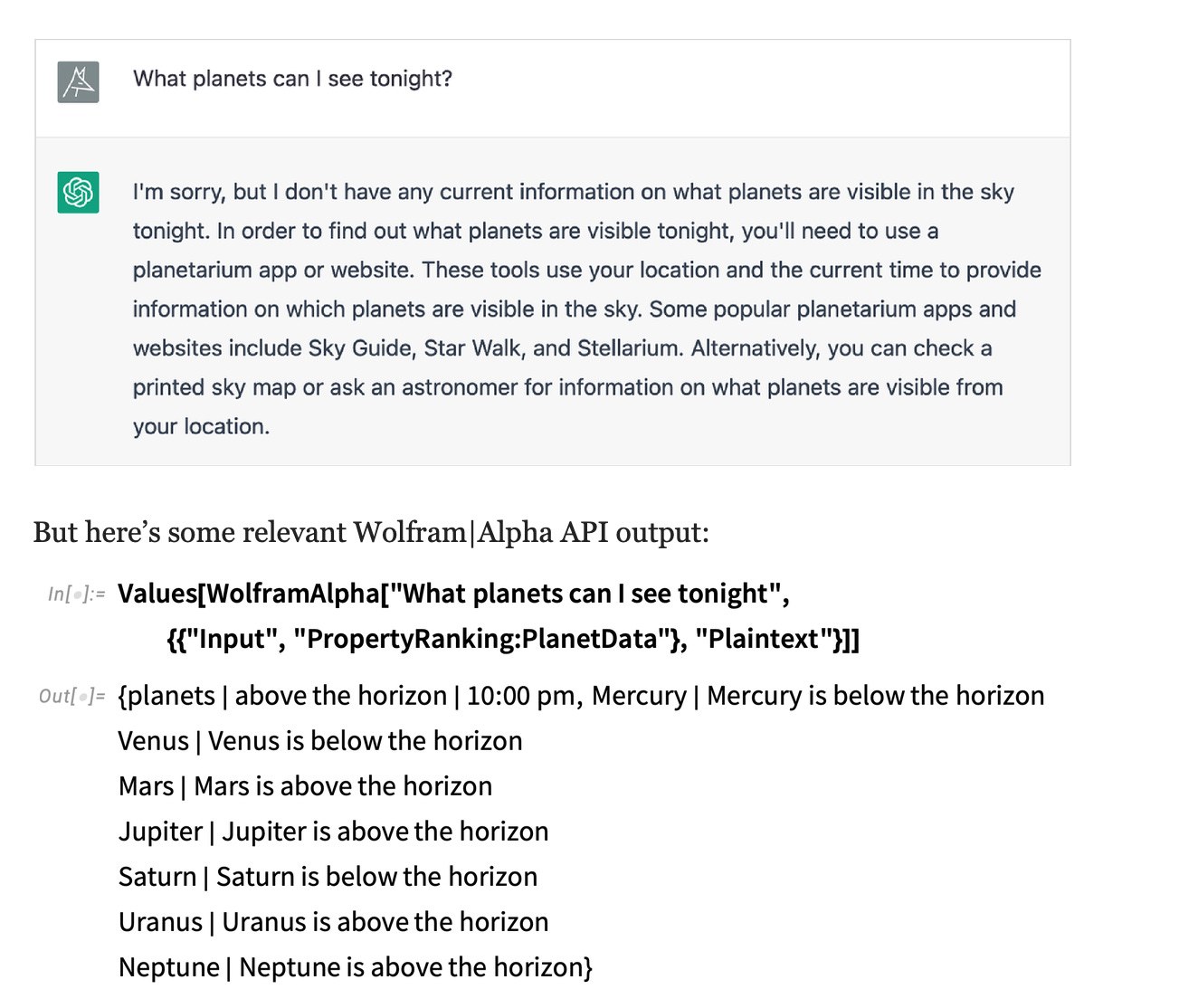
Note what is happening: chatGPT’s stochastic powers are no match for Wolfram Alpha’s formal precision, and the beauty of it all is that this is expected.
GPT-4 has no sense of world entities. It has no sense of distances, directions, or physics. It has no sense of logical assertions. It has no sense of numbers, geometries, or common sense. This does not mean that GPT-4 is useless. If anything, GPT-4 has opened our eyes to how much of human knowledge is plainly discoverable by parsing through billions of data points. Much of what we considered to be complex, human-only tasks, have turned out to be not so complex after all.
And this brings us to language, as promised earlier.
Languages, human or programming, are human constructs. They follow certain rules (called grammar) that define what the entities are (nouns, verbs, adjectives, etc.), how they interact, what rules of recursion they follow, and so on. But languages are not just about grammar. The sentence “I has a salad bowl for mine breakfast” is grammatically incorrect, while the (famous) sentence “Colourless green ideas sleep furiously” is grammatically perfect, but has some other inconsistency. What is it?
Semantics.
It makes “no sense”.
Language is only useful when the nuanced interplay between semantics and grammar hits the sweet spot. But that’s not all. Insofar as language is simply a human tool to be used solely for human purposes, as Wittgenstein believed, language is malleable. It allows for turns of phrase, irony, rhetoric, humor, and deconstructions. It feeds voraciously on context. “Colourless green ideas sleep furiously” may not be an attractive sentence to a modernist, but to a postmodernist, it may be the title of quite an avant-garde pop-up theatre masterpiece.
What chatGPT seems to have done, as Wolfram writes, is apparently discovering the rules of the English language quite efficiently. In fact, it might have, in its 175B matrices of representations, encoded an understanding of the English language (as far as grammar and foundational semantics are concerned) in a uniquely different way than humans have. What this representation is, we do not really know. Then again, we do not know how humans represent language either. But for millennia (or at least as far back as this question of human-machine intelligence was interesting), humans believed that language is complex and beyond the reach of machines.
GPT-4 puts a bold spanner in the works - As far as syntax is concerned, it seems languages are not really as complex as we believed them to be. In fact, this argument extends to programming languages as well, as my adventures with Github Co-Pilot have demonstrated.
But what about the language of Wolfram Alpha? How does it do what GPT-4 can’t?
Well, Wolfram Alpha (WA) operates on the Wolfram Language, another proprietary work of art from Mathematica - A customized symbolic language designed specifically for closed-ended queries (See here to clarify what I mean by a closed-ended query). All objects that we provide in the WA prompt are converted to entities in the Wolfram Language (in a similar way a parser-dependency tree works in programming languages)
How then, does WA connect these entities to understand the prompt in a human-understandable way?
The answer is even more astounding than Wolfram Language. For the past forty years, Wolfram Research has built a database of human concepts - The Name, Place, Animal, Things of our world - The Wolfram KnowledgeBase.
In Wolfram Language lies an implicit representation of what we mean when we ask “What is the distance between Los Angeles and New York?”
Wolfram Language knows that Los Angeles and New York are places, and thus have geo-coordinates. Wolfram Language knows what equation to use when a distance on a sphere is requested. GPT-4 does not know these things. It was never taught to know these things. It does not have a symbolic, formal, database , but an approximate distribution of a dataset. The entities it has learned are complementary to what exists in Wolfram KnowledgeBase.
GPT-4 is probability, Wolfram Alpha is logic. Reconcile the two, and you resolve the tension.
This is why Wolfram Research did the obvious - Integrate chatGPT with Wolfram Alpha. This plugin is only available for people with chatGPT-plus (a must-have for every human on Earth).
Instantaneously, GPT-4 answers correctly all those questions that it simply wasn’t designed to answer correctly.
In the near future, I envision larger systems that play off these two complementary ideas. In fact, it is unreasonable to assume that OpenAI, Anthropic, and all the other big players aren’t already exploring these options. Recall the value of human feedback. At the end of the day, hidden within GPT-4’s beautiful kaleidoscope of self-attention blocks (what truths do they hold?), there is also a simple feed-forward neural network whose only task is to predict how well a human would rate its own response.
Our logic-probability tension resolved, a new tension emerges:
When does GPT-X learn to play Name, Place, Animal, Things?